Exploring NLP with Coursera - Part 3
Two approaches to representing text
In this section we think of text as a sequence of words. Let’s look at two approaches of representing that sequence.
Bag of Words (BOW) way (sparse)
BOW is simply a vector where rows represent the sequence at hand (e.g. I saw a very good movie) and all the columns / features are a collection/dictionary of all words in a corpus. This dictionary can be huge (in the video ~100K words) thus making the list of our features enormous. Each sequence of words (sentence) would be a sum of vectors representing each of the words within that sentence, as illustrated in the image below. This representation is usually sparse since each sentence only has a limited number of words from the complete dictionary.

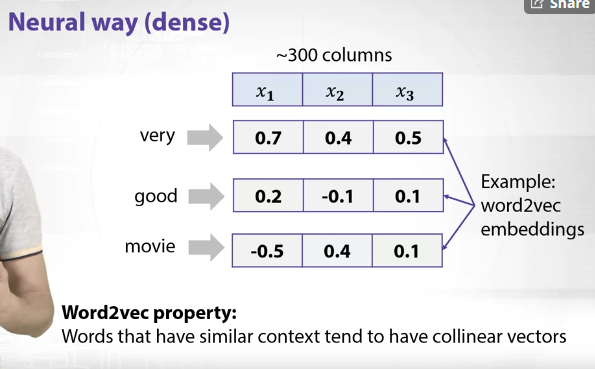
Neural network way (dense)
Contrary to BOW approach, a neural network approach would generate a dense matrix where each word would be represented by a vector which is shorter. An example of such representation is word2vec embeddings, a vector representation of words prepared in an unsupervised manner. Word2vec has a nice property = words that have a similar context tend to have collinear vectors (vectors that point to the same direction in vector space). For example, man and woman or king and queen would have close/similar values since they are similar in a certain manner. To come up with a feature descriptor or in other words to represent text we could also sum up all the vectors representing individual words. This could be a good baseline descriptor for text.
A better way: 1D convolutions
Basically, if we want to a vector representation of n-grams (in our case 2-grams), we can simply apply a confolutional filter on top of each token pair vectors (as illustrated) in order to generate a value which will be a vector representation of those two nearby tokens. Thus if we have two token pairs (1. cat sitting and 2. dog resting) which have similar meaning the result of using convolutional filter will be close. This is because word embeddings use cosine distance to calculate similarity of words, cosine distance is a dot product much like application of a convoluational filter. Thus at the end we get a high activation (0.9 and 0.84) which indicate these two 2-grams have a similar meaning (“animal sitting”). Of course, quality of word embeddings will also impact the quality of the n-grams.
Overall, this allows us to extract meaning from n-grams which can enable us to extract higher/abstract meaning from text.

1D convolutions
The benefit here is that this approach can be extended to many grams and the feature representation won’t expand since its fixed, thanks to word embeddings.
We use the convolutional filter (length 3 since we learn 2-grams) to slide the window through the sentence (“cat sitting there or here”). We would need to use many convolutional filters each of which would represents some sort of meaning. These filters are called 1D since we slide them in one direction. This order represents time. The results on the right are a vector representation of that convolutional filter.

We assume that we can lose the order of words which allows us to simply care about a certain meaning/combination ocurring in a sequence or not (e.g. animal sitting, since the filter would generate a high activation). Thus we choose the maximum value (0.7), which is called maximum pooling over time.

Final Architecture
Following the approach we can finally
- Use windows of size 3, 4, 5 to capture 3, 4, 5 grams
- Each window would have 100 convolutional filters
- This would generate 300 outputs / features
- Last, we train models on top of these features
There are two papers in here which have compared this approach of using 1D convolutions with maximum pooling to Naive Bayes on top of 1, 2 grams, with respective accuracies (slide below). As it seems this approach seems to be more effective in terms of accuracy of prediction.
Paper 1 - Natural Language Processing (Almost from Scratch)
Convolutional Neural Networks for Sentence Classification

Neural networks for characters
This time we can treat the text as a sequence of characters. We would need to hot encode our characters with the alphabet representing the rows of a matrix and each character along with space representing the columns. This matrix will be sparse but it won’t be that long, since the alphabet is finite.
Just like with words we start with n-grams here as well.
We use 1D convolutions on characters, starting with “c” character, we take the left as padding. We take a convolution and we get a result.

We get values for the 1st filter by sliding the window in one direction - time. Thus its also called 1D convolution.
Let’s say we use 1024 filters. Next we add pooling. For each filter we take pairs of values and only extract the maximum of those two values (Max Pooling). Then we slide the window to the next pair and so on.

We need pooling here since it introduces character position invariance, meaning even if the character n-gram slides one to right or left the activation in the pooling output will most likely stay the same.
We simply repeat this process of 1D convolution + max pooling.

The length of our feature representation decreases. We can do the pooling 6 times and our final architecture looks like this.

Below are the results of the experiments using the classical models and deep models (LSTM, Models with the above appoach)
We can observe that if the dataset is small classical models perform much better, whereas on big data deep models outperform the classical ones.
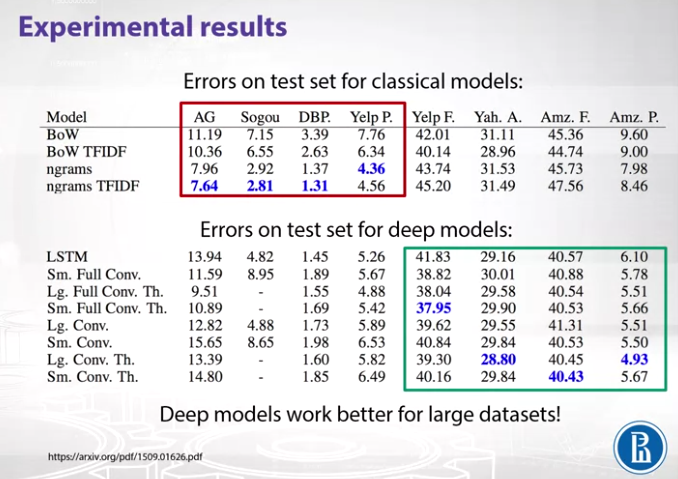
More details on the experiments can be access in this paper