Exploring NLP with Coursera - Part 2
Text Preprocessing
Text can be thought of as sequence of:
- Characters
- Words
- Phrases and named entities
- Sentences
- Paragraphs
Let’s start with words. Word - a meaningful sequence of characters. Usually we can find boundaries of words, with the exception of some words in German and all words in Japanese. To split a text into words we would need to tokenize the sentence.
Tokenization
Tokenization is a process that splits an input sequence into so-called tokens. Token is a useful unit for semantic processing. It could be a word, sentence, paragraph, etc.. A simple whitespace tokenizer is available in nltk, as an example:
from nltk.tokenize import WhitespaceTokenizer
s = "This is Andrew's text, isn't it?"
WhitespaceTokenizer().tokenize(s)
['This', 'is', "Andrew's", 'text,', "isn't", 'it?']
The problem of tokenizing in this way is that it? is the same as it and text, is same as text.
We can try to split by punctuation.
from nltk.tokenize import WordPunctTokenizer
s = "This is Andrew's text, isn't it?"
WordPunctTokenizer().tokenize(s)
['This', 'is', 'Andrew', "'", 's', 'text', ',', 'isn', "'", 't', 'it', '?']
The problem here is that 's or isn are not meaningful on their own.
To address these challenges we can use TreebankWordTokenizer which uses rules of english grammar to tokenize sequences.
from nltk.tokenize.treebank import TreebankWordTokenizer
s = "This is Andrew's text, isn't it?"
TreebankWordTokenizer().tokenize(s)
['This', 'is', 'Andrew', "'s", 'text', ',', 'is', "n't", 'it', '?']
Now 's and isn are more meaningful for processing. This tokenization method in this context makes more sense and allows us to tokenize the sentence in a meaningful way.
Token Normalization
The goal of token normalization is to remove insignificant differences between otherwise identical words to make for better searching and matching of same tokens.
For example, we may want the same token for different forms of words
- wolf, wolves –> wolf
- talk, talks –> talk
There are few ways of normalizing tokens. Most common ones are:
- Stemming
- Lemmatization
Both methods aim to reduce various forms of a word to a common base form. For example,
- am, are, is => be
- car, cars, car’s, cars’ => car
The result of this mapping of text will be something like:
- the boy’s cars are different colors => the boy car be differ color
However there are differences in the two methods. Stemming is a process of removing and replacing the ends of words (suffix, prefix) to get to the root of the word, called stem, while Lemmatization uses vocabulary and morphological analysis normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma.
Stemming Example
The most common algorithm for stemming English, and one that has repeatedly been shown to be empirically very effective, is Porter’s algorithm. It consits of 5 phases of word reductions, applied sequentially. Below is the example of phase I rule:

NLTK includes a porter stemmer module.
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
plurals = ['caresses', 'flies', 'dies', 'mules', 'denied', 'meeting',
'stating', 'siezing', 'itemization', 'sensational', 'traditional',
'reference', 'colonizer' 'plotted', 'feet', 'cats', 'talked', 'ponies']
singles = [stemmer.stem(plural) for plural in plurals]
print(' '.join(singles))
caress fli die mule deni meet state siez item sensat tradit refer colonizerplot feet cat talk poni
You can see from the example of feet that the stemmer fails on irregular forms and at times like with ponies produces non-words.
Lemmatization Example
A WordNet lemmatizer could be used to lookup lemmas.
from nltk.stem import WordNetLemmatizer
wordnetlemmatizer = WordNetLemmatizer()
plurals = ['caresses', 'flies', 'dies', 'mules', 'denied', 'meeting',
'stating', 'siezing', 'itemization', 'sensational', 'traditional',
'reference', 'colonizer' 'plotted', 'feet', 'cats', 'talked', 'ponies']
singles = [wordnetlemmatizer.lemmatize(plural) for plural in plurals]
print(' '.join(singles))
caress fly dy mule denied meeting stating siezing itemization sensational traditional reference colonizerplotted foot cat talked pony
The challenge here is that not all forms are lemmatized.
Ideally, the choice of lemmatization or stemming should be chosen based on the task at hand.
Further normalization
We can further normalize tokens in our text by applying certain logic. Let’s look at some of these.
Normalizing capital letters
In cases where capital letters are not necessary, we can lowercase capital letters. For example:
- Product -> product
- Us, us -> both are - us (in case both are pronoun).
- US vs us -> a bit tricky since US would mean USA and us would be pronoun.
Overall, to normalize capital letters we can use heuristics:
- lowercasing the beginning of the sentence
- lowercasing words in titles
- leaving mid-sentence words as they are
Its important to note that sometimes capitalization is needed for things like Named Entity Recognition, where we have named entities (e.g. Paris).
Another method to find out true casing of each words is using maching learning, but its quite hard and is out of scope of this class.
Acronyms
We can also normalize further by addressing acronyms such as:
- eta, e.t.a, E.T.A -> E.T.A.
- the US, u.s.a, U.S.A, U.S -> USA
- U.N, UN -> United Nations
A way to normalize acronyms would be writing regular expressions but its quite hard, since we need to think of all possible ways an acronyms could be written.
Feature extraction
Now that we have tokenized our text, we can move to extracting features from it. The first method is Bag of Words (BOW).
Bag of Words (BOW)
Basically, bag of words approach aims to vectorize the given text (text vectorization) by generating features which represent tokens in the text and their frequency of ocurrence within each text. Thus each token in the text will become a feature and the value of that feature will be a numeric value representing frequency or sometimes simply presence (0, 1). The representation allows us to find documents that are similar as well allows us to learn about the meaning of the document. If interested check out deep-dive into BOW here
Example of a BOW representation can be seen below

The limitations of BOW are:
- orders are not preserved (“good”, “movie” instead of “good movie”)
- counters are not normalized, thus some tokens will be more often than others or vice versa
To preserve token ordering, it’s possible to count token pairs, triplets, etc.
N-Grams
Simply put, n-gram is a sequence of N words (e.g. Orange county (2-gram), Johny likes coffee (3-gram)). By using n-grams we preserve local word order, but this approach can generate too many features at times growing exponentially due to combinations of words (e.g. it is a good and interesting movie, it is, a good movie, good and interesting movie, interesting movie).

We can remove:
- High-frequency n-grams - these usually are articles, prepositions, generally called stopwords (e.g. and, a, the). They are not useful since they won’t help differentiate texts.
- Low frequency n-grams - typos in text, rare words can influence the models to overfit, since these values obviously happen in a specific document and can be used as a differentiating factor
We are left with medium frequency n-grams. Now we can actually look at the frequency of these n-grams, just as we did previously, to differentiate between texts. For example, n-gram with smaller frequency can be more differentiating and would capture a specific meaning/issue in the text. To build on this idea we can use the notion of term frequency and inverse document frequency.
TF-IDF
TF-IDF, in a nutshell, is a measure that evaluates how relevant a word is to a document in a collection of documents and also indicates the oimportance of a term $t$ in a document $d$. It combines term frequency (TF) and inverse document frequency (IDF).
Term Frequency (TF)
Term frequency represents how many times a word/token appears in a document.
\[tf(t, d)\]frequency for term (or n-gram) $t$ in document $d$. There are different variants for calculating TF.
| Weighting Scheme | TF - Weight | Explanation |
|---|---|---|
| binary | 0, 1 | Simply take 0 or 1 based on whether the token is present in text or not |
| raw count | $f_{t, d}$ | Just a count of how many times a token occurs in a document, denoted $f$ |
| term frequency | $f_{t, d}/\sum_{t’\in{d}} f_{t’,d}$ | Look at all counts of all terms and then normalize the count of individual tokens across the document. Result is a sort of probability distribution |
| log normalization | $1+log(f_{t,d})$ | Use logarithmic scale of raw counts. Might help in solving the task better |
Inverse Document Frequency (IDF)
Next, let’s look at IDF. The inverse document frequency (IDF) is a is used for measuring the importance of a term in a text document collection. Let’s denote:
- $ N = |D|$ - total number of documents in corpus
- $|{d\in D:t\in d}|$ - number of documents where term $t$ appears
- $idf(t,D)=log(\frac{N}{|{d\in D:t\in d}|})$ - inverse document frequency
Now to computer TF-IDF we simply need to multiple the term frequency (TF) by inverse document frequency (IDF). \(tfidf(t, d, D) = tf(t, d) * idf(t, D)\)
A high weight in TF-IDF value is reached by a high term frequency and a low document frequency of the term in the whole collection of documents. The number of times a word appears in a document (term-frequency) is offset (inversed) by number of documents that contain the word (document frequency).
With this we are able to find information that is not as frequent in all documents but which captures critical information across the collection.
Now to use this idea and rethink our BOW we would get the normalized TF-IDF values in the vectorized representation. L2 normalization is an option.
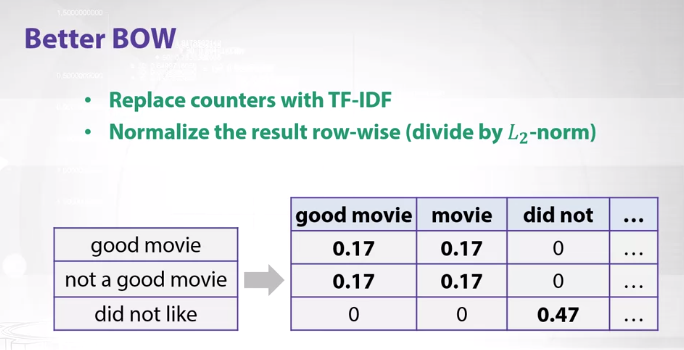
For example, good movie has 0.17 which means that it might not capture any specific information that might be valuable but “did not” has 0.47, indicating that we might be capturing some useful information. Let’s have a look at python implementation.
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
texts = ["good movie", "not a good movie", "did not like", "i like it", "good one"]
tfidf = TfidfVectorizer(min_df=2, max_df=0.5, ngram_range=(1,2))
features = tfidf.fit_transform(texts)
pd.DataFrame(
features.todense(),
columns=tfidf.get_feature_names()
)
good movie like movie not
0 0.707107 0.000000 0.707107 0.000000
1 0.577350 0.000000 0.577350 0.577350
2 0.000000 0.707107 0.000000 0.707107
3 0.000000 1.000000 0.000000 0.000000
4 0.000000 0.000000 0.000000 0.000000
In the code above we have
- min_df is a minimum document frequency that acts as a threshhold for terms ocurring in less than the min_df.
- max_df - maximum document frequency, maximum number of documents where we have seen that token, it can be represented as a ratio as well.
- ngram_range - n-grams eligible. In above code 1 or 2.
In the results not all n-grams are seen since they are filtered by our parameters.
Linear Models for Sentiment Analysis
Now that we have features developed, we will discuss first text classification model, specifically sentiment classification. For that we will use IMDB movie reviews dataset, which can be download here. The dataset is characterized as follownig:
- People rate the movies from 1 to 10 stars.
- It contains 25000 positive and 25000 negative reviews.
- Positive reviews (label=1) are those with at least 7/10 reviews
- Negative reviews (label=0) are those with at most 4/10.
- The dataset also contains at most 30 reviews per movie.
- It also provides a 50/50 train/test split.
- The model is evaluated based on - accuracy since the dataset is balanced (25000 positive and 25000 negative reviews)
Features: bag of 1-grams with TF-IDF values
Let’s start with first model. We have bag of 1-grams with respective TF-IDF values. That way we have 25000 rows with 74849 columns for training. Nevertheless, we get an extremely sparse matrix with 99.8 % of zeros.
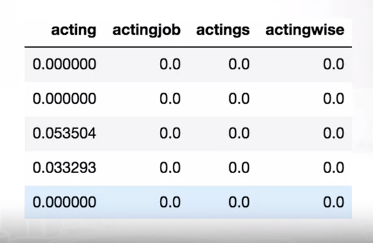
The fact of our training vector being so sparse applies some restrictions on what models we can use on top of these features.
One of the suitable options for this specific case is Logistic Regression. It tries to predict the probability of a review being positive given the features of a specific review or given the set of words in a review. Logistic Regression is a linear model and that’s why it can handle sparse data quite well and is fast to train, with further model weights being relatively easy to interpret.
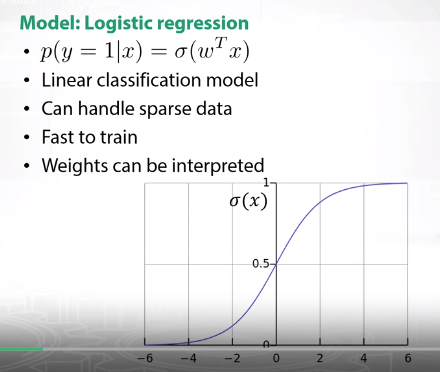
Basically, if the output of the linear combination of our features is 0 then the probability of the review being positive or negative is 0.5, which means we really don’t know, and if the output is more positive the more likely that the review is positive. Same logic for negative reviews. Interpretation of weights can be summarizes as such: if the weight of a specific word is negative then the word contributes to the overall review’s negative sentiment and vice-versa for positive weights.
These are the weights which we would get if we train a logistic regression over bag of 1-grams with TF-IDF values.

We can see that the model is performing better (88.5% accuracy) than random (50% accuracy) and it captured words that are positive and negative by assigning them related weights.
Better sentiment classification
Let’s try to make our model a little bit better. We can add 2-grams but only keep those that have been seen more than 5 times (potential typos and combinations that won’t add value to our model). We get 25000 rows with now whopping 156821 columns/features. We can see below that this model is also quite sparse.
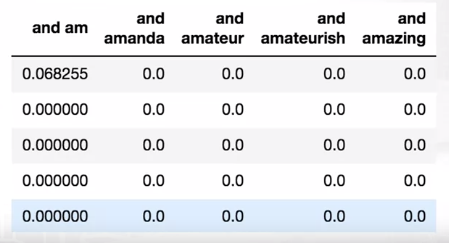
Let’s train our logistic regression over bag of 1,2 grams with TF-IDF values. Our model has a boost in accuracy with 89.9% (+1.5%). Now our model also includes 2-grams within the top positive and top negative weights.

How to make the model even better
There are couple of ways that we can increase the accuracy of our sentiment classifier.
- Play around with tokenization
- In reviews people use special tokens such as emojis (e.g. “:)”) and “!!!” can help. We can use those sequences of tokens and introduce to our model. This may or may not increase its performance.
- Try to normalize tokens
- We can normalize tokens by stemming or lemmatization
- Try different models
- We can also try models such as Naive Bayes, Support Vector Machines (SVM) and others that can handle sparse features
- Try Deep Learning
- We can try implementing deep learning on this dataset. The paper here has used Deep Learning on this IMDB dataset and as of 2016, the accuracy of this approach on test set is 92.14% (+2.5%). The accuracy gain from using deep learning is not as much considering the explainability of DLP vs Linear and other models.
Hashing trick in Spam Filtering
Before going forward with spam filtering task, let’s look at how we would handle mapping n-grams to feature indices. As a reminder, we want to represent our bag of words (BOW) in a vectorized format where n-grams are actually represented by their feature index or the index of the column where for example TF-IDF values would be stored. For that, we need to maintain a the mapping of n-grams to feature indices. There are two scenarios here:
- Small Dataset
- We simply store {n-gram -> feature index} hash map (or dictionary in python)
- Large Dataset
- In case of huge datasets (e.g. 1TB of text distributed on 10 computers) simply having a hash map becomes more challenging.
The first challenge with having a hash map in case of large datasets is that the hash map may not fit in the memory of one machine. We could use a database to store the correspondence of n-gram->feature index, but it doesn’t scale well since all our machines would depend on one database to store the correpondence. Another challenge is synchronizing across 10 machines the correspondence of n-gram->feature index, since if one machine updates the mapping then other would also need to do the same. This can become a bottleneck in the nlp pipeline.
There is an easier way, which is replacing the hash map with the hash value of the specific n-gram modulo 2^20, see below.

Hash is a function that converts the string into a number. For some strings, hash functions can produce same numbers, but despite that, in practice it works, and those collisions can be neglected if we take modulo of 2 to high power. This hashing has been implemented in scikit-learn and vowpal wabbit library.
Alright, now let’s take the Spam Filtering Task.
This is a huge task since people send a lot of emails. This paper explore a spam filtering task with a proprietary dataset which contains
- 0.4 million users
- 3.2 million letters
- 40 million unique words (features)
Let’s say we map each token to index using hash function \(\phi(x) = hash(x) \% 2^b\)
For b = 22 we only get 4 million features, which is a significant improvement over 40 million features. Despite having hash collisions, which are not a lot, the quality of the model is not hurt in this case.
Here is the example of the hashing vectorizer:

While the figure above is quite self-explanatory, the hashing collisions are there but there are not many of them in practice and they don’t affect the quality of the model. Also the vectorized matrix now consists features as hashed values of tokens.
We can go one step further and personalize spam filtering for users thanks to the hashing trick introduced earlier. To personalize, we simply need to take the BOW representation of our dataset and append the user data to it. Specifically:
- We take the scope of all emails in our spam filtering task with the associated user data.
- We generate BOW representation of all emails
- We append user data (e.g. USER123) to each token in BOW
- Pass through a hashing function (sum of two hashing functions)
Our initial hashing function \(\phi(x) = hash(x) \% 2^b\) would be slight modified to accomodate the personalized token representations, for another hash function \(\phi(x) = {hash(u + "\_" + token)} \% 2^b\)
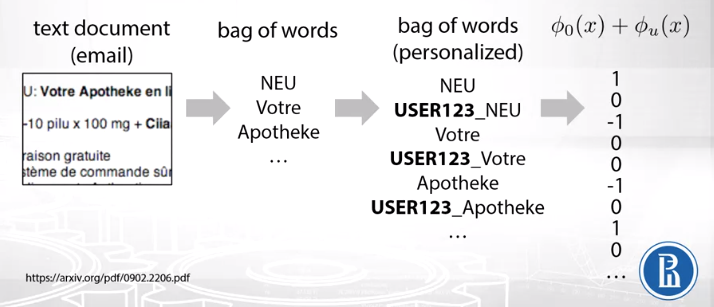
This is quite a nice trick since if we were to take the BOW of personalized representation of emails we would end up with 16 trillion features (user, word) but with this trick we still have $2^b$ features.
Experimental results
Now let’s look at the performance of various models.
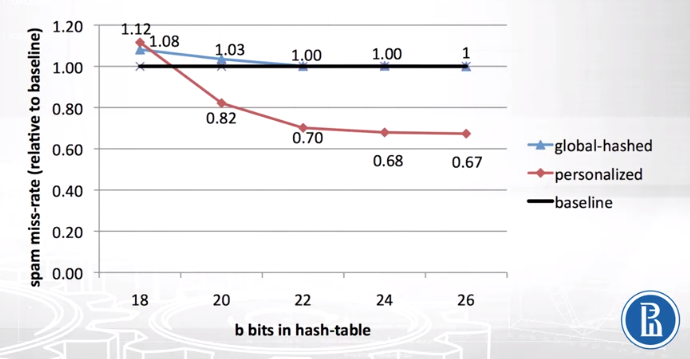
- Baseline model - simple linear model with original BOW token representation (TF-IDF vectors)
- Global-hashed - a linear model with hashing implemented (TF-IDF vectors replaces with hashed vectors)
- Personalized - a linear model with personalized tokens introduced and hashing implemented
We can see that the personalized model is significantly better than the other two and produces the lowest miss-rate (y-axis). The global-hashed model in comparison to baseline perform similar after b value of 22.
The reason why personalized model performs the best is simple. It captures “local” user-specific preferences. What is spam for me might not be a spam for you.
Now, how will this personalized model perform for new users.
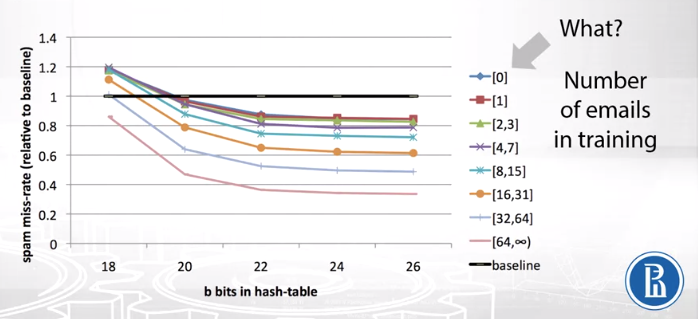
The graph above represents various models for only users which have a certain number of emails in training. For example, orange line represents the model trained on emails of users who had 16 to 31 emails in training set. If we look at the graph, ever for users with no emails in the training set our personalized model still outperformed the baseline model. It turns out that the model learns better “global” preferences having personalized features which learn “local” user preference. You can think of it this way, let’s say a small group of people marks newsletters as spam but the majority actually is fine with newsletters, thus while the model would learn that for those users newsletters are spam, in general newsletters are not spam. This is why even for people with no emails our personalized model performs better than baseline.
** Why the size matters
The size of the dataset matters because you can learn better models using just a simple linear classifier but having huge training data available. The authors of this paper on ad click prediction (with trillions of features, billions of training examples) showed that sampling data actually hurts the model (see figure below) with any sampling rate taken.

One might think that the difference in model performance (according to AUC) is not that significant, but in reality that improvement could generate millions of dollars in profit when it comes to ad click prediction.
Finally in this section, we would like to quickly introduce Vowpal Wabbit library.
- It is a machine learning library for training linear models
- Uses feature hashing internally
- Has lots of features
- Really fast and scales well
Programming Assignment
At this point in time the course provides a Programming Assignment on “Predicting tagson StackOverflow with Linear Models”. You can find my solutions to the assignment here.